人和智能体共享奖励参数,这才是强化学习正确的方向?
大模型驱动的 AI 助手又升级了。本周五,科技圈正在围观一个陪你一起玩《我的世界》的 AI。

它话不多说,就是埋头干活。一起盖房子的时候,你不需要给 AI 一张蓝图,或是不断告诉它该怎么做,你只需要盖自己的,它就能一边观察一边配合,并观察你的意图随时改变计划。

现在,AI 可以不断主动学习、纠正错误,展现出了此前大模型智能体无法实现的一系列能力。

看起来,新版的 AI 在与我们共同游戏时不再是催一下动一下了,它已经是一个有「主观能动性」的玩家,就像个和你共同玩过几百局游戏的老友一样。
这项技术名为 AssistanceZero,出自加州大学伯克利分校(UC Berkeley)。值得注意的是,它并未接受大模型常见的 RLHF 训练。相反,它是由「assistance games」强化学习驱动的,研究人员认为,这是构建 AI 助手的更好途径。
AI 在这个框架中并不会被动地接受人类反馈,而是寻求主动与人合作,通过推断目标而不断优化行为,这避免了 RLHF 中 AI 可能会出现的作弊行为,让 AI 可以采取更加协作的策略。

目标:把 RLHF 革命掉
最近,AI 领域里很多研究都在尝试改进或替代 RLHF。
我们知道,预训练、监督微调(SFT)以及基于人类反馈的强化学习(RLHF)或其变体已经成为训练通用 AI 助手的主要范式。RLHF 涉及对预训练的基础模型进行微调,使其根据人类标注者对诸如「帮助性」和「无害性」等标准的偏好来采取行动(即生成响应)。然而,通过 RLHF 训练的助手存在一些缺点:
- 标注者可能会被误导,对无帮助的行动给予积极的反馈,从而激励助手产生欺骗性或操纵性的行为。
- RLHF 并不鼓励模型保持对用户目标的不确定性,生成高评分单轮响应的目标使得助手不愿提出澄清问题或对其响应进行保留,像 GitHub Copilot 这样的非聊天型人工智能助手也存在类似的问题,当编码任务不明确时,Copilot 无法要求澄清。
- 像 Copilot 这样的自动完成助手也并未充分考虑助手行为的协作性 ——AI 助手的行动应补充用户的行为,而不是简单地预测或取代它们。
ChatGPT 倾向于用一个回复来解决你的所有问题。如果你要求 ChatGPT「清理一些磁盘空间」,它会给你一个程序运行,而不会询问哪些文件可以删除。
训练 AI 助手的另一种范式是 Assistance Games。它通过明确考虑协助的互动性和用户目标的不确定性,避免了 RLHF 的上述缺点。
具体来说,Assistance Games 是一个双人游戏,助手和用户在一个共享环境中采取行动。两个 Agent 共享一个奖励函数,但关键是助手最初对这个奖励函数是不确定的,assistance games 消除了欺骗的动机,因为助手的表现取决于真实的潜在奖励函数,而不是人类的反馈。此外,assistance games 还激励助手与用户互动以解决其不确定性。最后,解决 assistance games 的结果是助手的行动能够补充用户的行动,以实现最优的联合性能。而且,研究人员还设想了一种将 assistance games 应用于大语言模型后训练的方法,以替代 RLHF。
尽管 Assistance Games 具有诸多优势,但它们为何仍然是一个研究较少的训练 AI 助手的方法呢?Assistance Games 过去仅被用于解决非常简单的问题,但在复杂环境中却被广泛忽视,主要是由于以下看似不可克服的挑战:
- 计算上的难题:AI 助手需要在奖励函数的不确定性下保持决策能力,而这被认为是计算上不可行。
- 人类模型的准确性:与 RLHF 不同,解决 Assistance Games 需要一个能够准确预测人类对 AI 行动反应的模型。如果 AI 无法理解人类的沟通策略,可能会在与真实人类互动时表现不佳。过去关于 Assistance Games 的研究使用了基于强化学习或规划的人类模型,但这些模型可能与真实人类行为有显著差异。
该研究团队成功应对了这些挑战,并证明了复杂的 Assistance Games 是可以被有效解决的。为此,他们引入了一个新基准测试 —— Minecraft Building Assistance Game (MBAG)。
在这个测试中,AI 助手需要在《我的世界》游戏环境中帮助人类建造目标结构,但助手对目标一无所知。MBAG 的挑战在于目标结构的分布非常复杂,可能的目标数量超过 10^400 个,远远超过以往研究中的数量,同时状态和动作空间也更大。
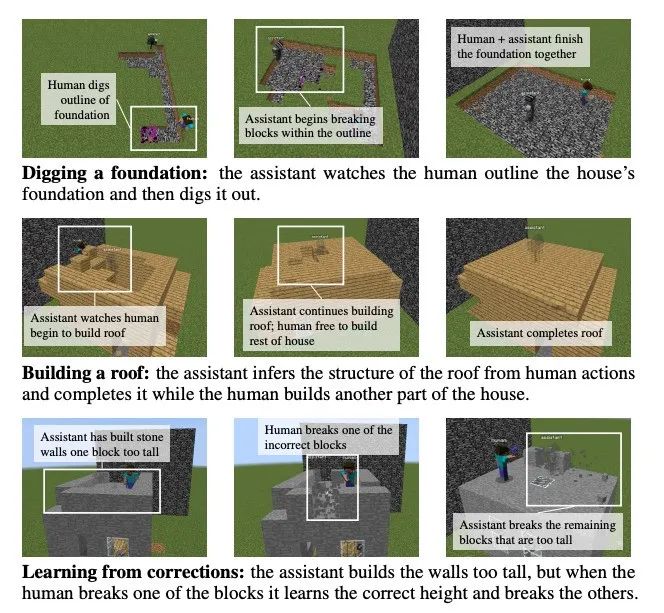
研究人员通过 MBAG 研究了深度强化学习算法是否能够解决 Assistance Games。研究发现,PPO(一种流行的无模型强化学习算法)可以轻松地在 MBAG 中建造已知目标房屋,但在目标结构未知时表现不佳。他们认为这是因为 PPO 需要同时从高方差的反馈中学习如何预测目标并根据预测采取行动,这增加了其难度。
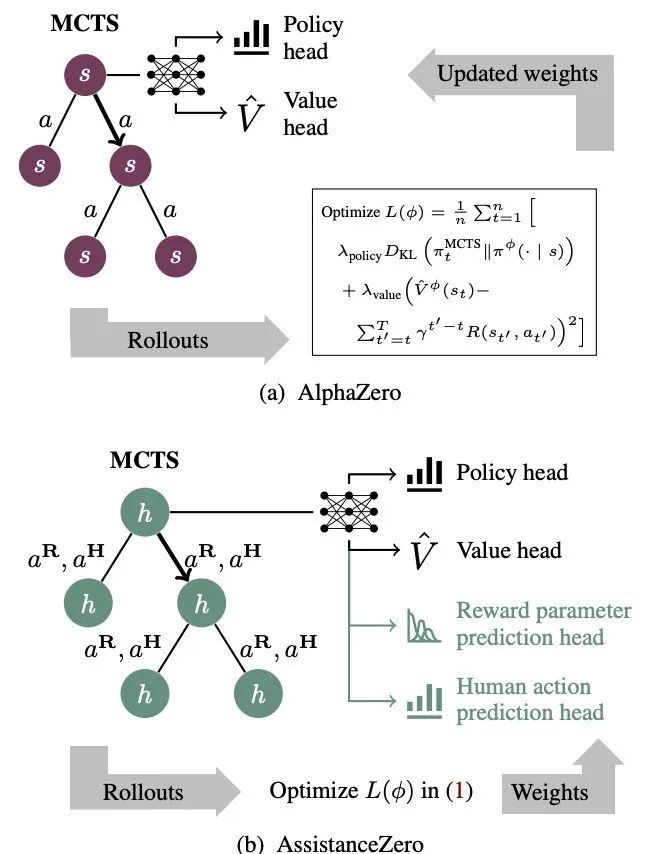
因此,为更好地解决 Assistance Games 问题,他们提出了一种名为 AssistanceZero 的新算法,该算法通过扩展 AlphaZero 来分离预测和行动。与 AlphaZero 类似,AssistanceZero 结合了蒙特卡洛树搜索(MCTS)和神经网络来选择行动。AssistanceZero 采用了一种具有额外输出层的神经网络,这些输出层用于预测奖励和人类行为,MCTS 利用这些预测在不确定性下有效规划。
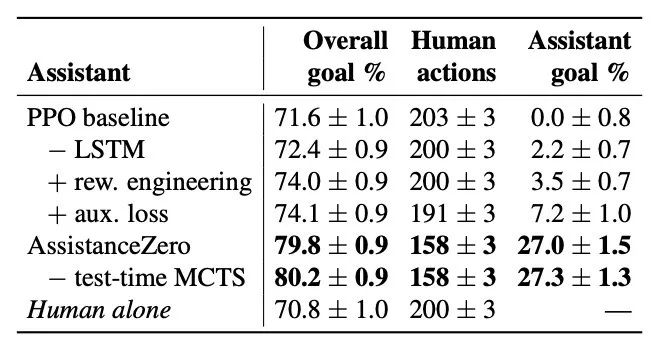
AssistanceZero 的效果远胜于 PPO。
此外,他们还通过探索如何开发出能产生有效助手的人类模型来应对解决 Assistance Games 的第二个挑战。有趣的是,他们发现 MBAG 中最佳的人类模型也结合了 MCTS 和模仿学习,这种方法被称为 piKL。
研究人员将通过 Assistance Games 训练的策略与其他方法(如类似预训练和 SFT 的流程)训练的策略进行了比较。
在 MBAG 中,他们发现通过 AssistanceZero 训练的助手在最佳人类模型和真实人类方面都大大优于通过预训练 + SFT 或其他方法训练的助手。AssistanceZero 助手展现了许多有用的自发行为,例如根据修正进行适应。
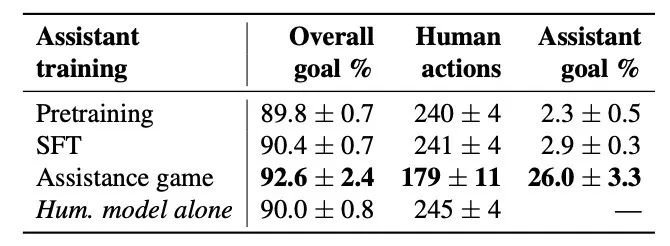
表3
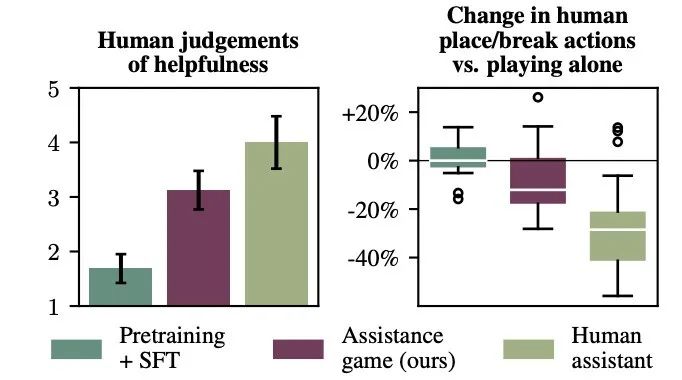
图2
总的来说,结果表明,Assistance Games 是可扩展的,并且可以成为在具有挑战性的环境中训练有用助手的优越框架。
什么是MBAG
在设计 MBAG 时,研究人员设定了几个目标,以使其成为一个更广泛研究协助游戏的有用环境。
其设计目标包括复杂的奖励参数分布、多样的助手帮助方式,以及适合学术实验室训练 RL agent 的环境。
MBAG 是由一个三维方块网格、网格内的玩家位置以及玩家的物品栏组成。网格中的每个位置可以是十种方块类型之一,包括空气,实验中使用了一个 11×10×10 的网格。
动作空间包括无操作、移动、放置方块和破坏方块。放置和破坏动作由位置参数化,放置动作还由方块类型参数化,这意味着在 11×10×10 的环境中,有超过 20000 种可能的动作。
玩家只能到达有限的距离来破坏或放置方块,而且在当前状态下,许多动作是无效的(例如,不可能破坏空气方块)。因此,通常只有一小部分动作是有效的。
提出 AssistanceZero 新算法
研究人员使用 MBAG 来研究如何解决协助游戏中的复杂序贯决策问题,并尝试了 PPO(一种无模型强化学习算法)训练助手策略。
然而,他们发现 PPO 在 MBAG 中表现不佳。使用循环 PPO 训练的助手根本无法帮助人类模型,而非循环 PPO 的表现略优于循环 PPO。他们认为,这是因为高方差的奖励信号使得 PPO 难以有效学习。
表1
此外,由于助手对目标结构不确定,即使根据观察历史,采取一个在期望中有帮助的动作有时也会导致负面奖励。任务的序贯性和长期性加剧了这些问题,进一步增加了 PPO 试图优化的奖励信号的噪声。
在训练初期,PPO 接收到的最明显的信号是放置和破坏动作往往是错误的,导致负面奖励。因此,助手策略收敛到几乎不建造任何东西。为了减少奖励信号中的噪声,并激励助手更多地采取行动,他们探索了仅根据助手自身动作的奖励来训练助手,还尝试添加一个辅助损失项,以鼓励放置正确的方块。
这些方法略微提高了助手 - 人类模型组合完成的目标百分比,同时减少了人类模型的动作数量或保持其不变。然而,它们仍然只是勉强有帮助。
为了解决 PPO 的局限性,他们设计了 AssistanceZero 来分离目标预测和行动选择,通过学习一个目标预测器,然后将其用于规划。
具体来说,AssistanceZero 是 AlphaZero 的扩展,AlphaZero 是一种在围棋和国际象棋等复杂竞争性游戏中取得超人表现的深度强化学习算法。
和 AlphaZero 一样,AssistanceZero 使用蒙特卡洛树搜索(MCTS)的一个变体来选择动作。MCTS 通过模拟从当前状态采取不同动作序列的结果来构建搜索树。然而,它需要知道奖励和动作导致的下一个状态,这两者在协助 POMDP 中都是未知的。
虽然作者已经证明 AssistanceZero 可以训练出与固定人类模型配合良好的助手,但如何先获得一个好的人类模型仍然不清楚。理想情况下,助手策略不仅应该与训练时使用的人类模型表现良好,还应该与真实人类配合时表现良好。他们探索了人类 AI 交互文献中开发 MBAG 人类模型的几种方法,包括基于奖励和基于数据的模型。
基于奖励的人类模型假设人类选择动作近似于最优,以最大化其奖励函数。他们使用深度强化学习训练了两个基于奖励的模型来独自建造目标结构。
对于其中一个模型,他们使用了带有熵系数的 PPO,近似于 Boltzmann 理性,这是一种常见的人类行为的噪声最优模型;另一个模型则使用了 AlphaZero 训练。
接下来,他们使用行为克隆(BC)训练了一系列基于数据的人类模型,行为克隆使用监督学习从状态预测动作。对于训练数据集,他们记录了五个受试者在 MBAG 中建造房屋的 18 个片段。
在一半的片段中人类独自建造,另一半则由一位有经验的《我的世界》玩家作为助手。他们将目标结构显示为受试者的一个半透明蓝图,覆盖在正常的游戏上,同时对人类助手隐藏目标结构。使用 BC,他们训练了三种人类模型:一种基于受试者独自游戏的数据(BC-alone),一种基于与助手一起游戏的子集(BC-with-assistant),以及一种基于整个数据集(BC-combined)。
虽然研究人员对 Assistance Games 的正式定义假设人类模型是马尔可夫的,但他们发现基于循环、历史的 BC 模型比马尔可夫策略更能预测人类动作。除了捕捉个别非马尔可夫行为外,循环人类模型还可以隐式地模拟多种人类策略的混合。这使得一个单一的循环模型有可能捕捉到真实人类技能水平的差异。
有望提升大模型后训练
在该研究中,研究人员实现了通过 Assistance Games 在 MBAG 中训练助手的完整方案,然后使用 AssistanceZero 求解生成的辅助 POMDP。如果将 Assistance Games 与其他 AI 助手训练范式进行比较会如何?
具体而言,作者开发了用于训练 MBAG 助手的流程,类似于 GitHub Copilot/OpenAI Codex 和 RLHF 的监督微调 (SFT) 阶段所使用的流程,这也是当前训练 AI 助手的两个主要范式。研究人员将生成的策略与使用 AssistanceZero 训练的助手进行比较。
RLHF 和 Codex 都以预训练语言模型为起点,这使得它们能够学习有用的表征并预测人类行为。在 MBAG 中,作者生成了一个预训练语料库,使用结合 BC 的人类模型生成 1 万个回合,该回合会从训练集 Dtrain 中随机选择目标结构进行构建。然后从观测值中删除目标结构信息,并在生成的数据集上训练一个循环神经网络(即预训练模型)。与语言或代码模型类似,该模型可以在没有目标信息的情况下预测人类行为,并学习到了能够理解人类目标结构的表征。
通过在低热状态下从预训练模型中采样动作,我们就获得了一个类似于 GitHub Copilot 的助手:当它对人类将采取的动作高度自信时,它会构建目标结构,缺乏自信时则不会采取行动。
进一步使用 SFT 训练预训练模型,其中使用人类专家作为助手的数据,对预训练模型进行微调以模仿人类助手,类似于在 RLHF 的 SFT 阶段训练 LLM 模仿人类书写的助手回复的方式。研究使用网格搜索对 540 个超参数组合进行搜索,以找到适合 SFT 策略的学习率、训练周期、数据增强和 dropout 的最佳组合。
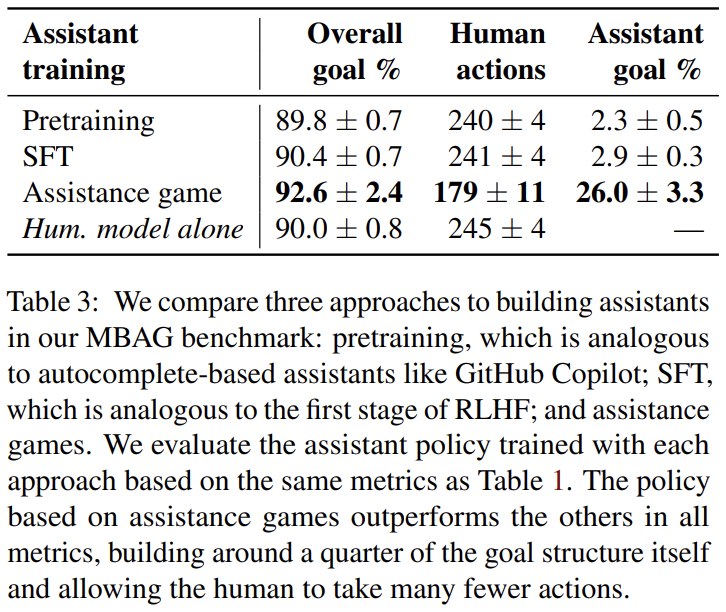
表 3 比较了预训练模型和 SFT 模型以及基于 Assistance Games 的策略。作者使用结合 piKL 的人类模型对每个模型进行了超过 1000 轮评估,并报告了与表 1 相同的指标。预训练策略和 SFT 策略均略微减少了实现相似目标完成率所需的人类操作数量(约 4-5 个)。SFT 策略平均构建了约 3% 的目标结构。相比之下,使用 AssistanceZero 训练的策略将人类操作数量减少了约 65 个,同时提高了目标完成率;它构建了约 26% 的目标。
作者还比较了 AI 助手与真人的表现。比较四种条件下的人类玩家:独自一人(无助手)、使用 SFT 策略、使用 AssistanceZero 训练的助手以及与专家人类助手一起进行游戏,每个参与者连续五次建造同一栋房屋。第一次用于练习,帮助受试者熟悉《我的世界》的操作和目标结构,随后受试者在四种条件下以随机顺序建造房屋。
在每次互动结束后,受试者对其整体实用性进行评分,结果显示经过 AssistanceZero 训练的助手表现明显优于 SFT 助手,并接近人类基准。其中,参与者对 AssistanceZero 能够从纠正中有效学习的能力印象深刻。例如,在人类破坏一两个错误方块后,AssistantZero 也能破坏多个错误方块,相比之下 SFT 助手则完全没有帮助。
伯克利的研究人员希望,基于 Assistance Games 的工作最终可以帮助大语言模型实现解决复杂问题的能力。
参考内容:
https://x.com/cassidy_laidlaw/status/1910708807258534008
感谢阅读!如果您对AI的更多资讯感兴趣,可以查看更多AI文章:GPTNB。
 { width=60% }
{ width=60% } { width=60% }
{ width=60% } { width=60% }
{ width=60% } { width=60% }
{ width=60% } { width=60% }
{ width=60% } { width=60% }
{ width=60% }

