机器之能原创
作者:sia
以大模型、AIGC为代表的人工智能浪潮已经在悄然改变着我们生活及工作方式,但绝大部分人依然不知道该如何使用。
因此,我们推出了「AI在用」专栏,通过直观、有趣且简洁的人工智能使用案例,来具体介绍AI使用方法,并激发大家思考。
我们也欢迎读者投稿亲自实践的创新型用例。
投稿邮箱:content@jiqizhixin.com
无论用哪种模型生成精美图片,提示语都会包含对调色板的要求。
想要营造日落的氛围感觉?
一定要提示,使用温暖、明亮的日落色调。
还要强调色调给人的感受,如一种壮丽、瑰丽的感觉。

提示语:Portrait of a charming lady , sunset-inspired hues, epic mood
营造复古氛围?
一定要用柔和并带有陈旧感的色调,比如橘黄、暖棕、深绿。
还要告诉大模型,希望色调传达出一种类似看到自然奇观、宗教圣地时被激发出的那种感觉。
结果,我们做出了这张复古风的甲壳虫图片。

提示语:Portrait of A vintage beeetle car, Retro inspired colors, Awe-inspiring mood
这种白/灰与橙色的搭配创造出强烈的视觉对比,使图像更有吸引力和戏剧性。

提示语:Portrait of a robot, Deotone colors palette, Bold mood
从装修房子、买家具,到网站、作品设计,配色在日常生活中随处可见。
但是,选择色调常常是一场痛苦的拉锯战,也是一个专业活儿。

好了,现在有帮手了!除了文字、视频、图片,AIGC 还能直接生成调色板!
这个很小众的 AIGC 应用 ColorAI ,是一个调色板生成器,只要写出自己的创意和设计理念,它就能自动生成配色。

视频链接:https://mp.weixin.qq.com/s/d2Y2ANwaPxWpvswJmlllug
这个 ColorAI 和一般设计类 AI 有点不同,它会解释为什么这些颜色非常适合你的创意。
一旦看懂效果和寓意,咱们这些完全不懂设计的人也能自信地选出满意的方案。
-1-
看懂 ColorAI
ColorAI 的界面很简单,但要读懂,还得费点功夫。
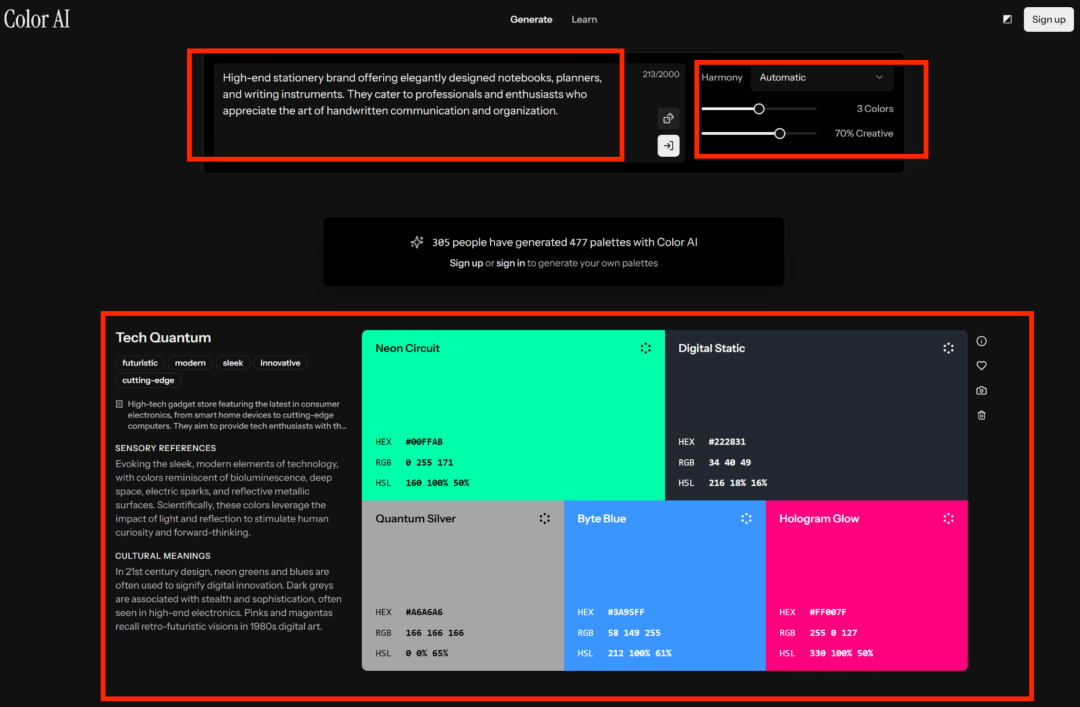
上方(左):输入自己的创意理念,如你要设计什么、希望传递一种什么样的理念和感受;
上方(右):调整命令遵循的程度、选择配方方案;
填写、选择完毕,即可点击生成,得到一套配色方案(下方)。
ColorAI 提供了五个常见的配色方案:
Triadic、Analogous、Compound、Complementary、Monochromatic

不想太费脑子了解?你可以选择「自动」,让系统为你决定。
但了解这几个方案,有助于更快找到更合适的配色。
Triadic ,三元色配色方案。
在标准的12 色色轮上选择三个相隔 120 度的颜色,如红、黄、蓝。

这种配色方案是几种方案中最均衡的,因为颜色丰富,通常会有鲜明的视觉对比效果。
你可以在很多日出、日落的自然风景图片中看到这种配色。

这张约翰·列侬是典型的三元色配色方案,视觉冲击力很强。

Analogous,相似色配色方案。选择色轮上相邻的颜色,比如,黄、黄绿、绿。
因为选择的是色轮上相邻的颜色,所以整体效果非常和谐,视觉上平滑过渡,让人感到舒服。
ChatGPT 网页设计就是一个相似色的配色方案,蓝色和粉红色在色轮上相对接近,中间以紫色作为过渡,创造出柔和而和谐的视觉效果。
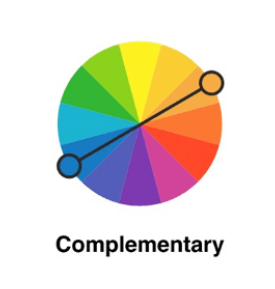
Complementary,互补色方案。选择色轮上对立的两种颜色。
蓝橙就是一组经典的冷暖互补色,我们常说的红配绿,也是一种互补色方案。
这个房间设计就是互补色方案,例如蓝色和橙色,这些互补色很好地结合在一起,因为它们在视觉上相互平衡,明亮的橙色提供温暖和亮度,平衡深钴蓝色。

Compound,复合色配色方案。选择一种基本颜色作为主色,然后,找到这个主色在色轮上的对面的色(距离最远的那个,也就是互补色),选择互补色两侧相邻的颜色与之搭配,而不是直接使用互补色。

你可以将 TA 视为「互补色方案 」的减轻版——仍然是强烈对比,但更为柔和,减轻了眼睛的负担,颜色选择也更多。
Monochromatic ,单色方案。使用同一种颜色,但不同明度、饱和度和深浅来打造和谐的视觉层次。
寻找配色方案时,这是最为 easy 的模式,几乎不会踩雷。


-2-
牛刀小试
现在,我想设计一个心理健康 App 界面。
「想为一款心理健康应用程序设计一个令人平静和宁静的配色方案,用户一看到这些颜色,就会感到放松和平和。」
配色方案,选择「自动」,立刻得到一组配色方案。
总体感觉,结合了海水的蓝绿色、沙滩的浅色和日落时的温暖色调,视觉上令人愉悦和放松。
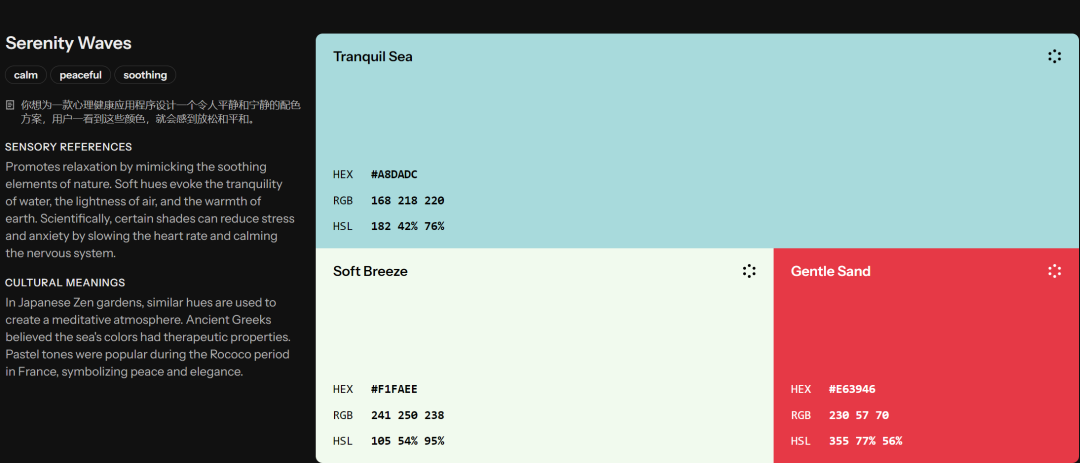
可能你也注意到了,每个颜色的面积大小不一样。
其实,这是一个设计原则的体现:
最好不要均匀分布这些颜色,相反,选择一个颜色占主导地位。
如大面积使用的 「Tranquil Sea(宁静的海)」,一种柔和的浅蓝绿色。
另外两种颜色用来强调它:
一个是 「Soft Breeze(柔和的微风)」,一种非常浅的米色;
另一个是 「Gentle Sand(温和的沙)」,一种柔和的珊瑚红。
通常,这些配色的黃金比例是 60:30:10
除了颜色配比,可能你还注意到,每个颜色的右下方有三组编码。
以 Tranquil Sea(宁静的海)为例。
感谢阅读!如果您对AI的更多资讯感兴趣,可以查看更多AI文章:GPTNB。






 从原画到建模
从原画到建模




